
大模型训练
Pre-training
Post-training
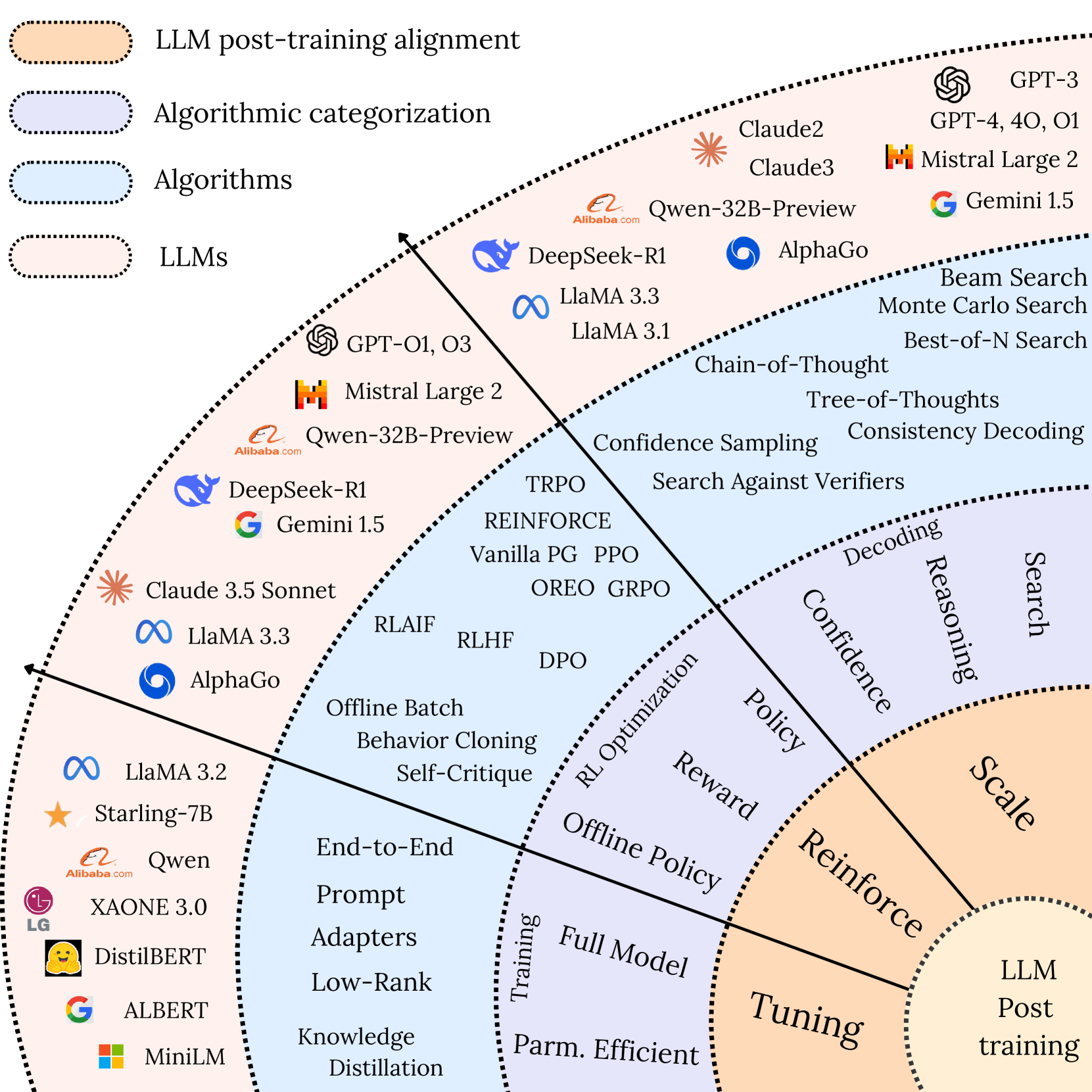
对于私有化,或有垂直行业需求的开发者,一般需要对模型进行二次训练(微调,对齐等),在训练后进行评测和部署。从训练角度来说,需求一般是:
- 具有大量未标注行业数据,需要重新进行CPT。一般使用Base模型进行。
- 具有大量问答数据对,需要进行SFT,根据数据量选用Base模型或Instruct模型进行。
- 需要模型具备独特的回复能力,额外做一次RLHF。
- 需要对模型特定领域推理能力(或思维链)增强,一般会用到蒸馏、采样微调或GRPO[3]
Fine-tuning
微调预估显存消耗[4]
| Methods | Bits | 7B | 14B | 30B | nB |
|---|---|---|---|---|---|
Full (bf16 or fp16) | 32 | 120 GB | 240GB | 600GB | 18nGB |
Full (pure_bf16) | 16 | 60 GB | 120GB | 300GB | 8nGB |
| Freeze/Lora/GaLore/APOLLO/BAdam | 16 | 16 GB | 32GB | 64GB | 2nGB |
| QLoRA | 8 | 10 GB | 20GB | 40GB | nGB |
| QLoRA | 4 | 6 GB | 12GB | 24GB | n/2GB |
| QLoRA | 2 | 4 GB | 8GB | 16GB | n/4GB |
Reinforcement Learing
GRPO 全量微调显存需求[5]
| Method | Bits | 1.5B | 3B | 7B | 32B |
|---|---|---|---|---|---|
| GRPO Full Fine-Tuning | AMP | 2*24GB | 4*40GB | 8*40GB | 16*80GB |
| GRPO Full Fine-Tuning | BF16 | 1*24GB | 1*40GB | 4*40GB | 8*80GB |
训练框架
hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs & VLMs (ACL 2024)
volcengine/verl: verl: Volcano Engine Reinforcement Learning for LLMs