
Group Relative Policy Optimization (GRPO)
DeepSeekMath + TRL + verl(TODO)
Introduction
The mathematical reasoning capability of DeepSeekMath is attributed to two key factors: First, we harness the significant potential of publicly available web data through a meticulously engineered data selection pipeline. Second, we introduce Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO), that enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO.
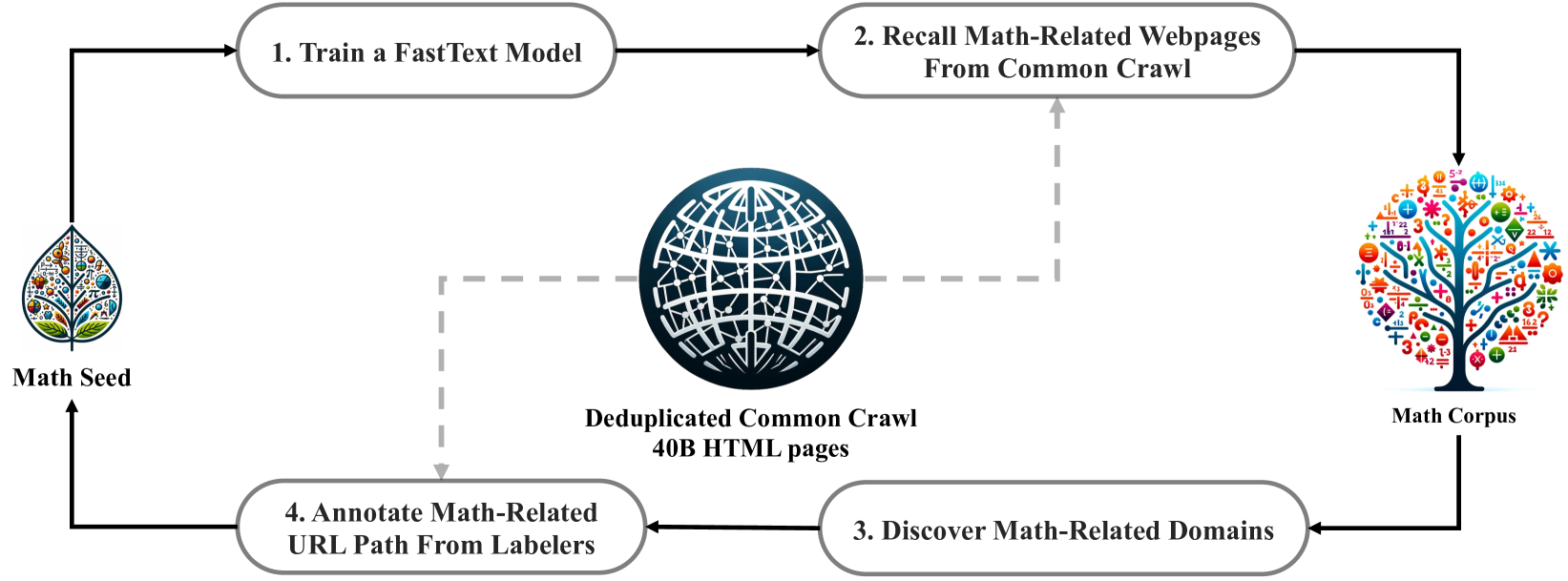
精心设计的数据筛选流程
群体相对策略优化算法 (GRPO)
一些观察(结论?)
- 模型的数学训练不仅增强数学能力,还放大了一般推理能力
- 统一范式下,不同的方法都被概念化为直接或简化的 RL 技术
- 参数量并非数学推理能力的唯一关键因素,高质量数据集也十分重要
- 先验的代码训练可以提高模型解决数学问题的能力/推理能力
- ArXiv 论文似乎在改进数学推理方面无效
- 强化学习过程中,模型跨领域性能有所提升
- 以英语为中心的数学语料库可能阻碍中文数学推理的表现
- 实时数据采样将提供更大的优势
- 使用细粒度、阶跃感知梯度系数,迭代 RL 可以显著提高性能
- RL 通过使输出分布更加稳健来提高模型的整体性能,似乎归因于提高 Top K 的正确响应
Data
Reinforcement Learning
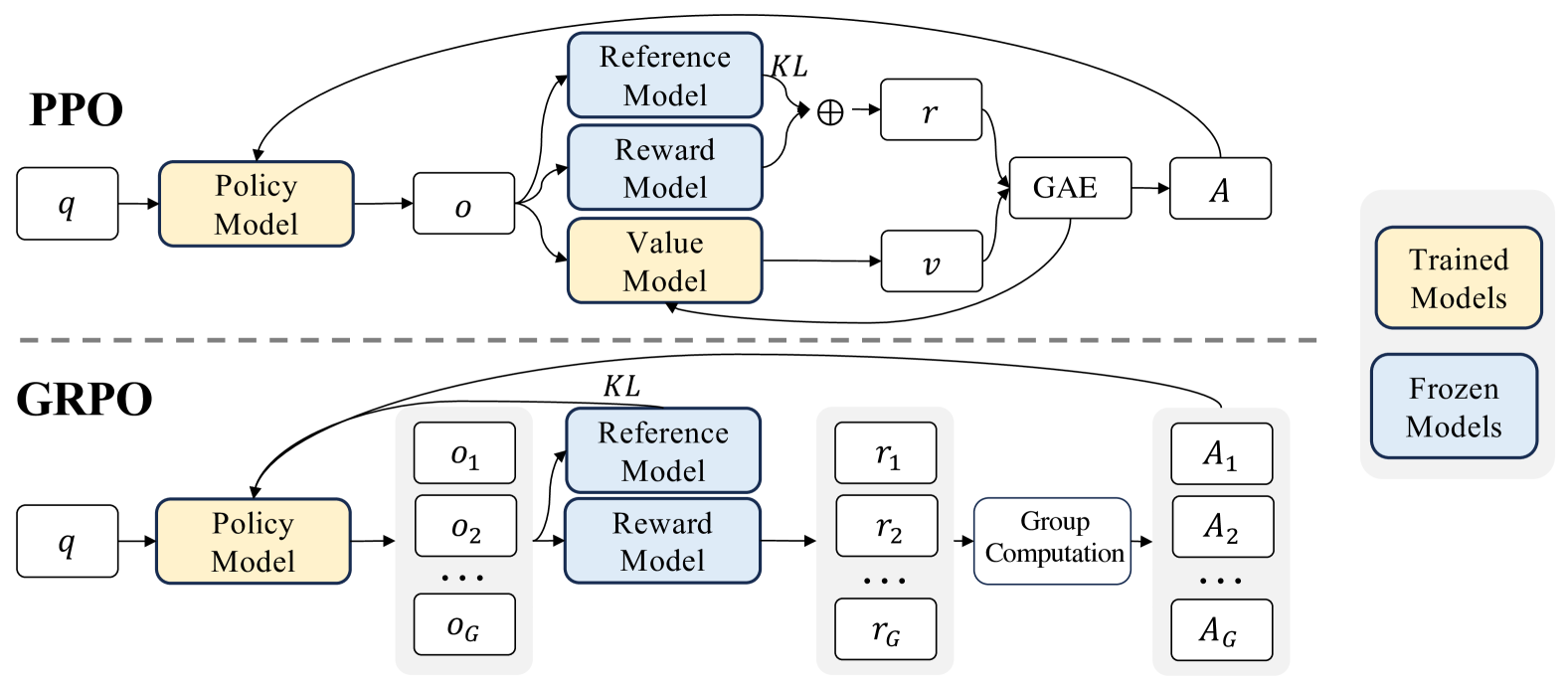
Generally, the gradient with respect to the parameter θ of a training method can be written as:
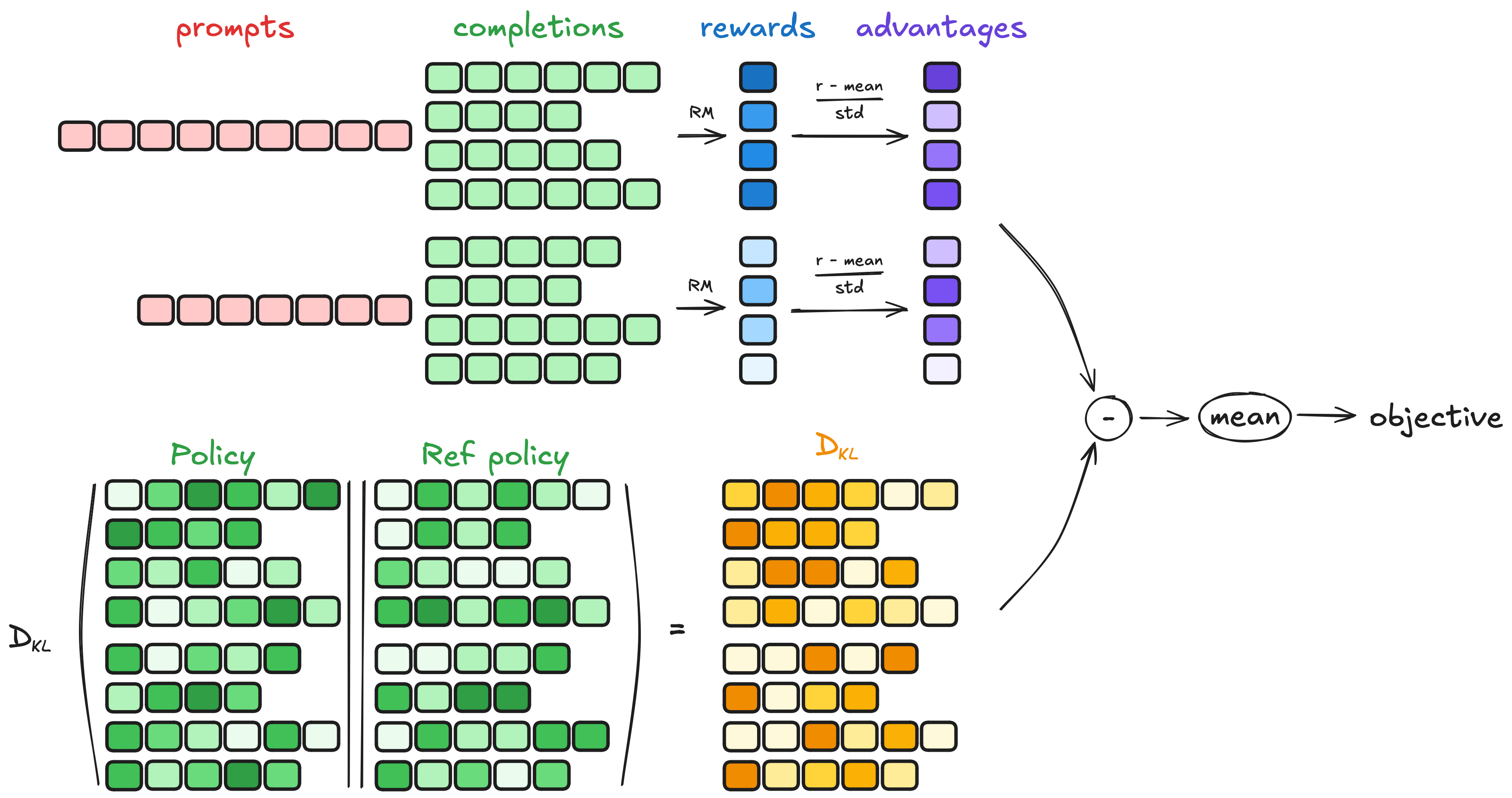
GPRO formula:
Estimating the KL divergence(评估两个模型的相似度):
Computing the advantage:
Loss (in original TRL):
where clip(⋅,1−ϵ,1+ϵ)clip(⋅,1−ϵ,1+ϵ) ensures that updates do not deviate excessively from the reference policy by bounding the policy ratio between 1−ϵ1−ϵ and 1+ϵ1+ϵ. In TRL though, as in the original paper, we only do one update per generation, so we can simplify the loss to the first form.
- 结果监督 RL
- 过程监督 RL
- 迭代 RL:训练 Reward Model 以保证对不断更新的 Policy Model 的合理评估