
大模型的后训练
Post-training
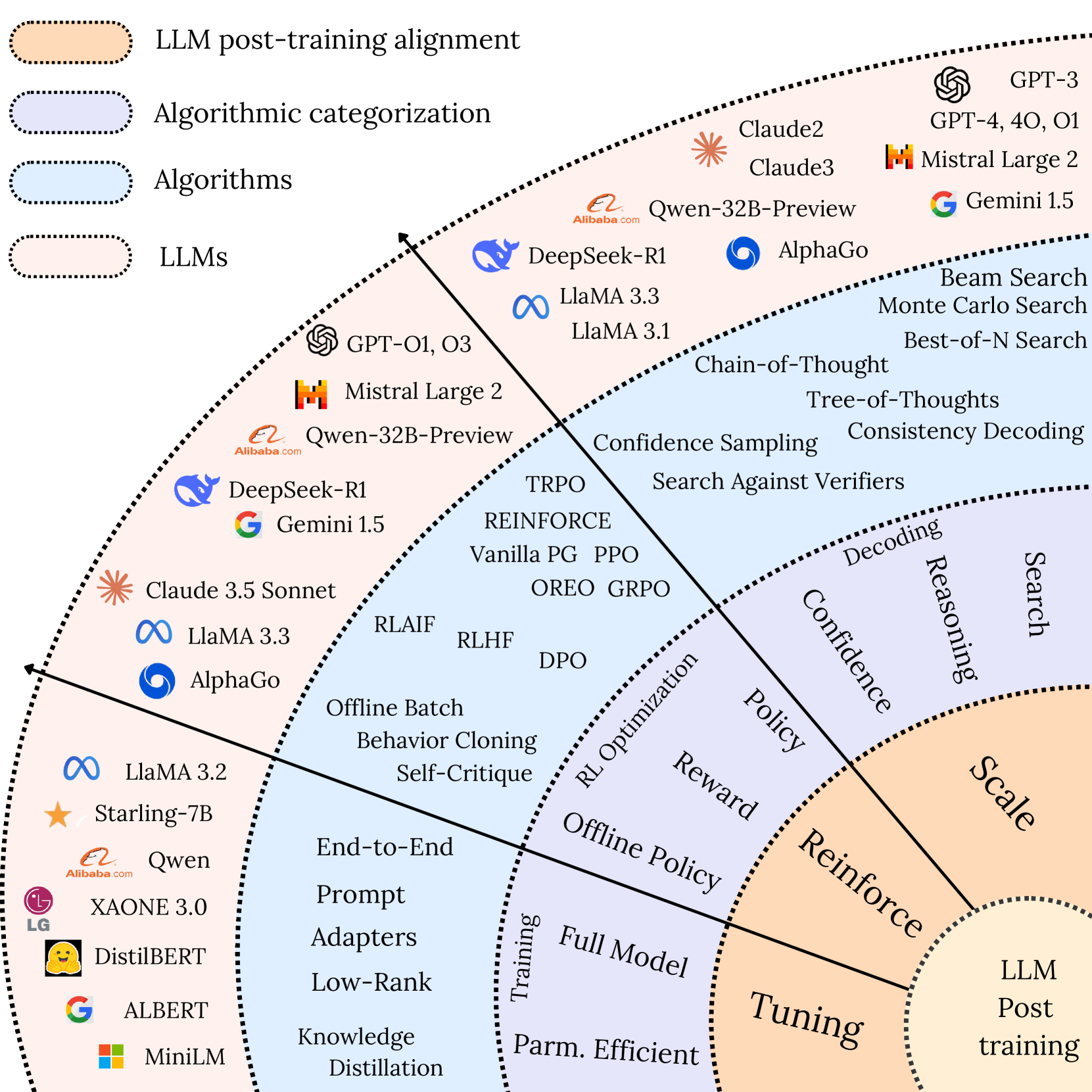
对于私有化,或有垂直行业需求的开发者,一般需要对模型进行二次训练(微调,对齐等),在训练后进行评测和部署。从训练角度来说,需求一般是:
- 具有大量未标注行业数据,需要重新进行CPT。一般使用Base模型进行。
- 具有大量问答数据对,需要进行SFT,根据数据量选用Base模型或Instruct模型进行。
- 需要模型具备独特的回复能力,额外做一次RLHF。
- 需要对模型特定领域推理能力(或思维链)增强,一般会用到蒸馏、采样微调或GRPO[3]
Fine-tuning
微调预估显存消耗[4]
| Methods | Bits | 7B | 14B | 30B | nB |
|---|---|---|---|---|---|
Full (bf16 or fp16) | 32 | 120 GB | 240GB | 600GB | 18nGB |
Full (pure_bf16) | 16 | 60 GB | 120GB | 300GB | 8nGB |
| Freeze/Lora/GaLore/APOLLO/BAdam | 16 | 16 GB | 32GB | 64GB | 2nGB |
| QLoRA | 8 | 10 GB | 20GB | 40GB | nGB |
| QLoRA | 4 | 6 GB | 12GB | 24GB | n/2GB |
| QLoRA | 2 | 4 GB | 8GB | 16GB | n/4GB |
Reinforcement Learing
GRPO 全量微调显存需求[5]
| Method | Bits | 1.5B | 3B | 7B | 32B |
|---|---|---|---|---|---|
| GRPO Full Fine-Tuning | AMP | 2*24GB | 4*40GB | 8*40GB | 16*80GB |
| GRPO Full Fine-Tuning | BF16 | 1*24GB | 1*40GB | 4*40GB | 8*80GB |
训练框架
hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs & VLMs (ACL 2024)
volcengine/verl: verl: Volcano Engine Reinforcement Learning for LLMs
LoRA
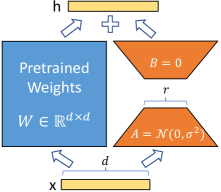
LoRA[6]是一种参数高效微调方法,用于将大语言模型适应到下游任务。LoRA 显著减少了可训练参数的数量和 GPU 内存需求,同时实现了与完全微调相当甚至更优的性能,并且独特之处在于它不引入额外的推理延迟。
假设:适应过程中的权重更新具有较低的“内在秩。
Weight updates during adaptation have a low "intrinsic rank.
对于任何预训练权重矩阵
其中
在训练期间,原始权重
其中:
- 矩阵
用随机高斯值初始化,而 初始化为零,确保训练开始时 - 对
应用缩放因子 ,以在改变秩 时减少超参数敏感性
Reference
LLM Post-Training: A Deep Dive into Reasoning Large Language Models | alphaXiv ↩︎
A Survey on Post-training of Large Language Models | alphaXiv ↩︎
xming521/WeClone: 欢迎star⭐。🚀从聊天记录创造数字分身的一站式解决方案💡 使用微信聊天记录微调大语言模型,让大模型有“那味儿”,并绑定到聊天机器人,实现自己的数字分身。 数字克隆/数字分身/数字永生/声音克隆/LLM/大语言模型/微信聊天机器人/LoRA ↩︎
[2106.09685] LoRA: Low-Rank Adaptation of Large Language Models ↩︎